
Blick hinter den Hype: Was Studien wirklich über KI in der Software-Entwicklung verraten
Es vergeht kaum ein Tag ohne neue Erfolgsmeldungen über Künstliche Intelligenz. Gerade in der IT- und Software-Entwicklung versprechen Anbieter-Fallstudien regelmäßige Durchsatzsteigerungen von 50 bis 66 Prozent. Auch die bekannte McKinsey Global Survey prognostizierte immense Potenziale und schätzte, dass Generative KI (GenAI) die Produktivitätsrate im Software-Sektor massiv heben wird. GitHub Copilot und ähnliche Tools werden als die ultimativen Beschleuniger vermarktet, die Entwickler „um ein Vielfaches schneller“ machen.
Wenn wir jedoch die oft beschönigten Marketing-Zahlen der Software-Anbieter verlassen und harte wissenschaftliche sowie industrieanalytische Quellen hinzuziehen, ergibt sich ein völlig anderes, stark kontrastiertes Bild. Als Unternehmen, das seit über 50 Jahren Software für den öffentlichen Verkehr und Mobilität entwickelt, wissen wir bei MENTZ: Nachhaltige Software-Architektur basiert nicht auf Hype, sondern auf empirischer Realität.
Ein kritischer Blick auf den aktuellen Stand der Studien zerlegt die gängigen Mythen und hinterfragt die Methodik der Datenerhebung.
Das Produktivitäts-Paradoxon in der Software-Entwicklung
Der gängige Mythos besagt, dass Entwickler durch KI-Copiloten in Rekordzeit fehlerfreien Code ausgeben. Die empirische Realität sieht jedoch differenzierter aus.
Der Code-Qualitäts-Einbruch
Eine systematische Metastudie von Mohamed et al., veröffentlicht in der California Management Review, wertete 37 unabhängige Studien zu LLM-Assistenten (Large Language Model) in der Software-Entwicklung aus. Das Ergebnis: Während Entwickler zwar weniger Zeit für das Schreiben von reinem Boilerplate-Code (Standard-Codebausteine) oder für API-Suchen brauchten, kam es zu massiven Qualitätsrückgängen. Die anschließende Fehlersuche (Debugging) und das Umschreiben fehlerhafter oder suboptimaler KI-Vorschläge fraßen die gewonnenen Geschwindigkeitsvorteile im Aggregat häufig komplett auf.
Die Experten-Falle
Eine Untersuchung zur Software-Entwicklung an einem US-Tech-Support-Desk von Brynjolfsson et al. deckte eine signifikante Asymmetrie auf. Eine Produktivitätssteigerung war fast ausschließlich bei den untersten 25 Prozent der Belegschaft – also Junioren oder neuen Mitarbeitern – messbar. Hier zeigte sich ein Durchsatz-Plus von rund 35 Prozent.
Bei erfahrenen Senior-Entwicklern gab es dagegen nahezu keine messbaren statistischen Gewinne. Der Grund: Top-Experten mussten überproportional viel Zeit investieren, um subtile, logische Fehler der KI zu korrigieren – Fehler, die Junioren oft komplett übersehen. Für die Architektur komplexer, sicherheitskritischer Systeme im öffentlichen Raum ist diese Fehleranfälligkeit ein hohes Risiko.
Der methodische Messfehler
In einer großangelegten empirischen Analyse im ACM Queue Journal entlarvten Jenna Butler und weitere Forscher bei Microsoft den fundamentalen Messfehler der optimistischen Studien:
„Wir wissen bereits, dass Entwickler nicht die meiste Zeit mit dem Schreiben von Code verbringen; Studien bei Microsoft und anderswo zeigen, dass dies eher bei 14 % liegt. Das bedeutet, dass die KI-Codegenerierung, selbst wenn sie gut funktioniert, einen überraschend kleinen Teil der eigentlichen Arbeit berührt. Und dennoch verdoppeln Organisationen den Einsatz von Lines-of-Code-Metriken, um die Wirkung von KI zu verfolgen – ein Maß, das weder statistisch valide noch sinnvoll mit Ergebnissen wie Softwarequalität oder Liefergeschwindigkeit verknüpft ist.“
Der „Pilot-Stau“ und die Projektabbruch-Quote
In der Praxis scheitern KI-Initiativen in der IT-Infrastruktur weit häufiger, als Management-Berichte vermuten lassen. Viele Projekte verbleiben dauerhaft im Versuchsstadium oder werden vorzeitig beendet.
Die nackten Zahlen namhafter Analysten belegen diesen Trend:
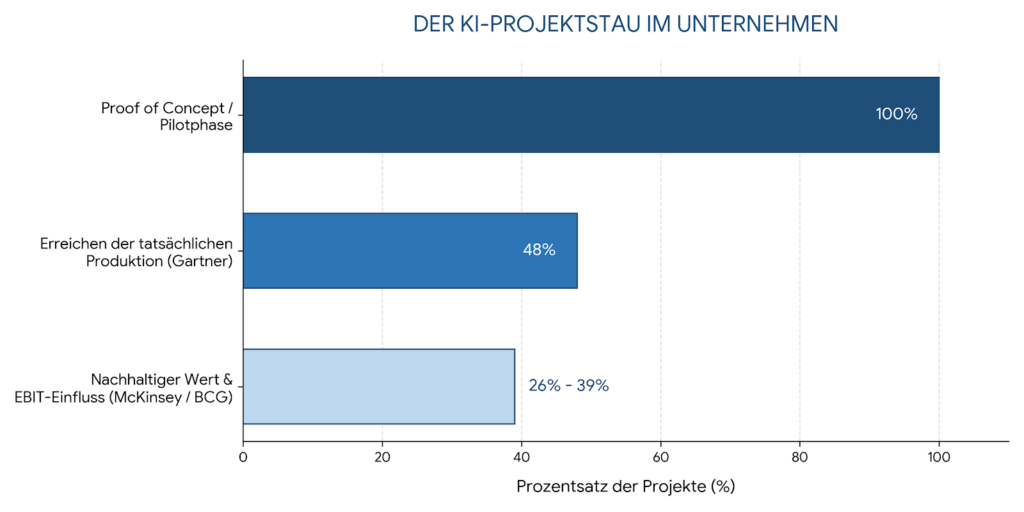
- Gartner Group: Erhobene Daten zeigen, dass im Schnitt nur 48 Prozent aller Enterprise-KI-Projekte überhaupt jemals die Testphase verlassen und den Status einer echten produktiven Anwendung (Production) erreichen. Zudem prognostizierte Gartner, dass mindestens 30 Prozent aller generativen KI-Projekte nach dem Proof-of-Concept wegen explodierender Kosten, mangelnder Datenqualität oder unklarem Business-Value komplett abgebrochen werden.
- S&P Global (451 Research): Die Analysten dokumentierten einen massiven Anstieg des sogenannten Scaling Paradoxons. Der Anteil der Unternehmen, die die Mehrheit ihrer KI-Initiativen noch vor dem Produktivgang einstampfen mussten, schoss innerhalb eines Jahres von 17 Prozent auf 42 Prozent hoch.
- Rand Corporation / IEEE: Analysen von realen IT-Projekten zeigen, dass über 80 Prozent aller KI-Projekte scheitern. Das entspricht exakt der doppelten Ausfallquote im Vergleich zu klassischen, nicht-KI-basierten Software- und IT-Projekten.
Kosten und ROI: Wo sich die Daten widersprechen
Während die Zahlen zur IT-Infrastruktur ein kritisches Bild zeichnen, existieren beim Return on Investment (ROI) im Software-Bereich die tiefsten Gräben zwischen den unterschiedlichen Studien.
Widerspruch 1: Großes vs. kleines Budget
Eine großangelegte Feldstudie von Denis Atlan, die 200 reale B2B-Software-Deployments analysierte, brachte ein statistisch signifikantes und kontraintuitives Ergebnis hervor:
- IT-Projekte mit kleinen Budgets (< 10.000 €) erzielten einen finalen Median-ROI von +245 %.
- IT-Großprojekte mit Budgets über 100.000 € sackten auf einen Median-ROI von gerade einmal +85 % ab.
Die Erklärung für dieses Phänomen liegt in der Struktur großer Enterprise-Architekturen. Diese leiden unter extremem Scope Creep (uferlose Anforderungsänderungen), bürokratischer Komplexität und massiver Erwartungsinflation. Kleinere, agile und hochgradig spezialisierte Micro-Tools performen finanziell drastisch besser.
Widerspruch 2: Der EBIT-Mythos
In der McKinsey Global Survey gaben 39 Prozent der Organisationen an, dass KI einen messbaren Einfluss auf ihr EBIT (Betriebsergebnis) hatte. Schaut man tiefer in die Daten des MIT Sloan Management Review, relativiert sich diese Aussage sofort: Lediglich 6 Prozent der Unternehmen werden dort als „High Performer“ eingestuft, die mehr als 20 Prozent ihres EBITs wirklich kausal auf eine erfolgreiche KI-Integration zurückführen können.
Zusammenfassung: Konsens vs. Dissens in der Fachwelt
Aus den aktuellen IT- und Software-Engineering-Daten lassen sich klare Schnittmengen und fundamentale Diskrepanzen filtern, die für die strategische Ausrichtung von Mobilitäts- und Softwareprojekten entscheidend sind.
Hierüber herrscht Konsens (Einigkeit unter fast allen Quellen)
- Das Daten-Problem als Showstopper: Die primäre Ursache für das Scheitern von Enterprise-KI ist in der Regel nicht das gewählte KI-Modell (ob OpenAI, Anthropic oder Open-Source), sondern eine mangelhafte interne Dateninfrastruktur. Der Global CDO Insights Survey identifiziert unzureichende Datenqualität (43 Prozent) als das Haupthindernis. Ohne valide, strukturierte Daten liefert auch die beste KI keine verlässlichen Ergebnisse.
- Die Verdopplung der Ausfallwahrscheinlichkeit: Seriöse Quellen wie Gartner, die Rand Corporation und die IEEE bestätigen übereinstimmend, dass das Risiko, ein KI-Softwareprojekt nicht erfolgreich abzuschließen, exakt doppelt so hoch ist wie bei normaler Software-Infrastruktur.
- Die Asymmetrie der Nutzung: KI-Tools helfen im Coding-Bereich nachweislich Anfängern und Junioren beim Einstieg. Für Top-Experten und Senior-Entwickler, die komplexe Systeme pflegen, stellen sie jedoch oft ein Nullsummenspiel oder sogar eine Bremse dar, da aufwendige Code-Reviews zur Vermeidung von Halluzinationen notwendig sind.
Hierüber herrscht maximaler Dissens (Widersprüche)
- Die Definition von „Produktivität“: Während Ökonomen und Managementberatungen Produktivitätsgewinne oft stur in „generierten Zeilen Code pro Stunde“ oder „schneller geschriebenen Texten“ messen, weisen empirische Software-Studien nach, dass diese Metrik fehlerhaft ist. Nachgelagerte Fehlerbehebungen und tiefe Architektur-Inkompatibilitäten werden in den optimistischen Reports meist verschwiegen.
- Tatsächlicher finanzieller Ertrag (ROI): Die Spanne reicht von ruinösen Infrastrukturkosten durch hohen Token-Verbrauch und unvorhersehbare API-Preismodelle bis hin zu über 300 Prozent ROI bei kleinen, isolierten Einzellösungen. Ein allgemeingültiges, verlässliches betriebswirtschaftliches Kostenmodell für Enterprise-KI existiert de facto noch nicht – es bleibt hochgradig kontextabhängig.
Fazit für die Praxis
Die Daten zeigen deutlich: KI ist kein Allheilmittel, das per Knopfdruck die Software-Entwicklung revolutioniert. Wer KI-Projekte unvorbereitet und ohne fundierte Datenbasis startet, läuft Gefahr, im „Pilot-Stau“ stecken zu bleiben oder an der Experten-Falle zu scheitern. Genau hier wird die fundierte Expertise von erfahrenen Partnern wichtiger denn je.
Um das tatsächliche Potenzial von Künstlicher Intelligenz auszuschöpfen, kommt es darauf an, die passenden, wirtschaftlich sinnvollen Use Cases präzise zu identifizieren und sie nahtlos in bestehende, komplexe Systemarchitekturen zu integrieren. Genau das ist unsere Kernkompetenz: Bei MENTZ verbinden wir über 50 Jahre Domänenwissen im öffentlichen Verkehr mit moderner Technologie. Wir wissen, an welchen Stellen KI-gestützte Tools Arbeitsprozesse wirklich effizienter gestalten – sei es bei der intelligenten Datenaufbereitung, der Automatisierung von Standardprozessen oder der Unterstützung bei der Systemanalyse –, und wo die menschliche Qualitätssicherung unverzichtbar bleibt.
Wir freuen uns sehr darauf, diesen Weg gemeinsam mit unseren Kunden zu gehen. Die digitale Transformation des öffentlichen Verkehrs bietet enorme Chancen, und wir stehen bereit, um als starker Partner aus vagen KI-Versprechen messbare, verlässliche Erfolge für Ihre Mobilitätslösungen zu machen. Lassen Sie uns die Zukunft der Mobilität gemeinsam intelligenter gestalten.
Quellen:
- ACM Queue Journal (Microsoft-Forschung zu Mythen im SE):Eight Myths on Software Engineering and GenAI
- arXiv (Studie zum Produktivitäts- und Qualitäts-Paradoxon):The Productivity-Reliability Paradox
- arXiv (Empirische Studie zur 80%-Ausfallquote):The Machine Learning Canvas Study
- arXiv (Analyse zu Investitionen, EBIT und KI-Bereitschaft):Why AI Readiness Is an Organizational Learning Problem
- Denis Atlan Forschungsbericht (PDF zur ROI-Budget-Analyse):AI ROI Analysis: Evidence from 200 B2B Deployments
- Management & Data Science Review (Zusammenfassung der ROI-Studie):Management & Data Science Article
- IEEE Xplore (Gartner-Daten & Datenqualität-Showstopper im PRISE-Framework):PRISE Framework for AI Product Incubation